AI tools for Large Language Models
Related Tools:
Ollama
Ollama is an AI tool that allows users to access and utilize large language models such as Llama 3, Phi 3, Mistral, Gemma 2, and more. Users can customize and create their own models. The tool is available for macOS, Linux, and Windows platforms, offering a preview version for users to explore and utilize these models for various applications.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.
Infermatic.ai
Infermatic.ai is a platform that provides access to top Large Language Models (LLMs) with a user-friendly interface. It offers complete privacy, robust security, and scalability for projects, research, and integrations. Users can test, choose, and scale LLMs according to their content needs or business strategies. The platform eliminates the complexities of infrastructure management, latency issues, version control problems, integration complexities, scalability concerns, and cost management issues. Infermatic.ai is designed to be secure, intuitive, and efficient for users who want to leverage LLMs for various tasks.
Cohere
Cohere is the leading AI platform for enterprise, offering products optimized for generative AI, search and discovery, and advanced retrieval. Their models are designed to enhance the global workforce, enabling businesses to thrive in the AI era. Cohere provides Command R+, Cohere Command, Cohere Embed, and Cohere Rerank for building efficient AI-powered applications. The platform also offers deployment options for enterprise-grade AI on any cloud or on-premises, along with developer resources like Playground, LLM University, and Developer Docs.
Cohere
Cohere is the leading AI platform for enterprise, offering generative AI, search and discovery, and advanced retrieval solutions. Their models are designed to enhance the global workforce, empowering businesses to thrive in the AI era. With features like Cohere Command, Cohere Embed, and Cohere Rerank, the platform enables the development of scalable and efficient AI-powered applications. Cohere focuses on optimizing enterprise data through language-based models, supporting over 100 languages for enhanced accuracy and efficiency.

Dust
Dust is a customizable and secure AI assistant platform that helps businesses amplify their team's potential. It allows users to deploy the best Large Language Models to their company, connect Dust to their team's data, and empower their teams with assistants tailored to their specific needs. Dust is exceptionally modular and adaptable, tailoring to unique requirements and continuously evolving to meet changing needs. It supports multiple sources of data and models, including proprietary and open-source models from OpenAI, Anthropic, and Mistral. Dust also helps businesses identify their most creative and driven team members and share their experience with AI throughout the company. It promotes collaboration with shared conversations, @mentions in discussions, and Slackbot integration. Dust prioritizes security and data privacy, ensuring that data remains private and that enterprise-grade security measures are in place to manage data access policies.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
Weam
Weam is an AI adoption platform designed for digital agencies to supercharge their operations with collaborative AI. It offers a comprehensive suite of tools for simplifying AI implementation, including project management, resource allocation, training modules, and ongoing support to ensure successful AI integration. Weam enables teams to interact and collaborate over their preferred LLMs, facilitating scalability, time-saving, and widespread AI adoption across the organization.
ProtestGPT
ProtestGPT is an activist AI tool created by Micah White that utilizes OpenAI's GPT-4 and Large Language Models to generate unique and unconventional protest ideas on any given topic. It helps activists come up with innovative strategies for building movements and bringing about change by providing campaign concepts, theories of change, press releases, social media posts, step-by-step guides, and more.
Spellbook
Spellbook is a comprehensive AI tool designed for commercial lawyers to review, draft, and manage legal contracts efficiently. It offers features such as redline contract review, drafting from scratch or saved libraries, quick answers to complex questions, comparing contracts to industry standards, and multi-document workflows. Spellbook is powered by OpenAI's GPT-4o and other large language models, providing accurate and reliable performance. It ensures data privacy with Zero Data Retention agreements, making it a secure and private solution for law firms and in-house legal teams worldwide.
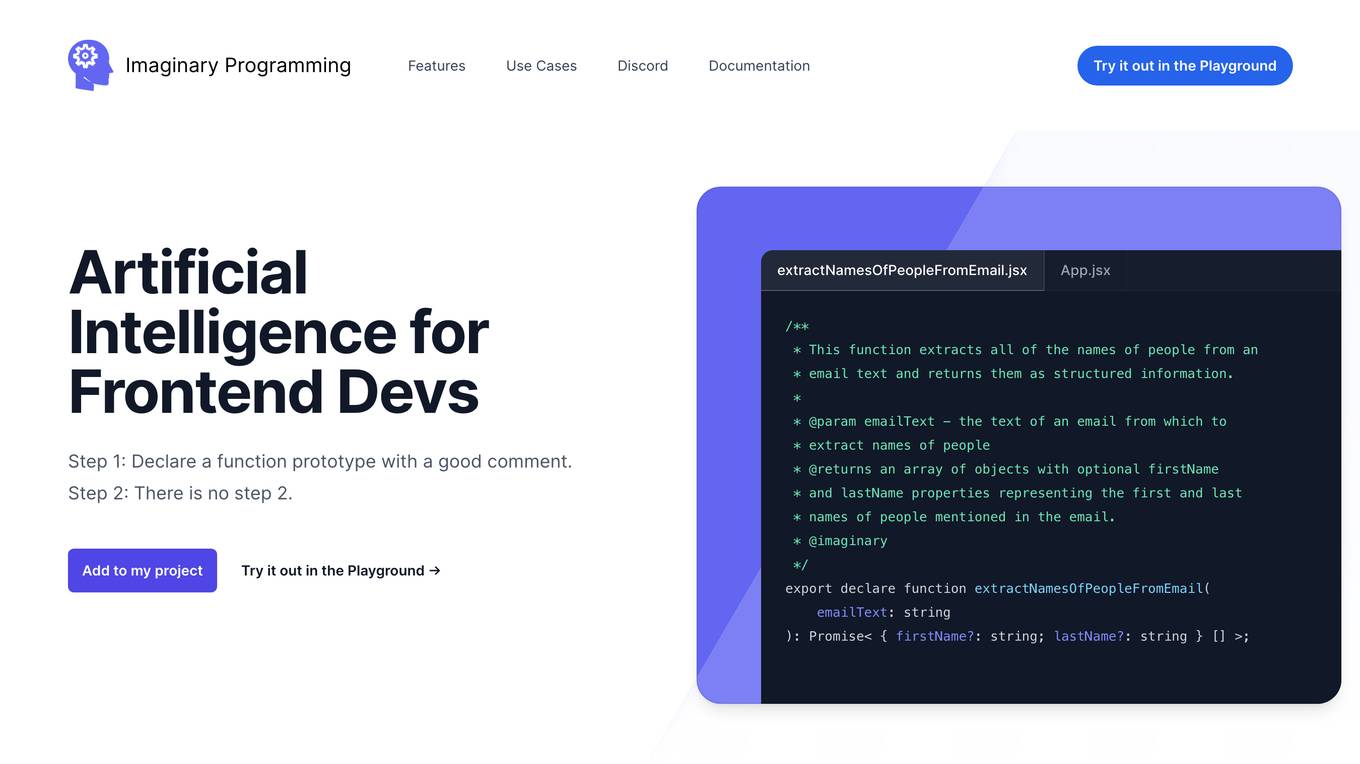
Imaginary Programming
Imaginary Programming is an AI tool that allows frontend developers to leverage OpenAI's GPT engine to add human-like intelligence to their code effortlessly. By defining function prototypes in TypeScript, developers can access GPT's capabilities without the need for AI model training. The tool enables users to extract structured data, generate text, classify data based on intent or emotion, and parse unstructured language. Imaginary Programming is designed to help developers tackle new challenges and enhance their projects with AI intelligence.
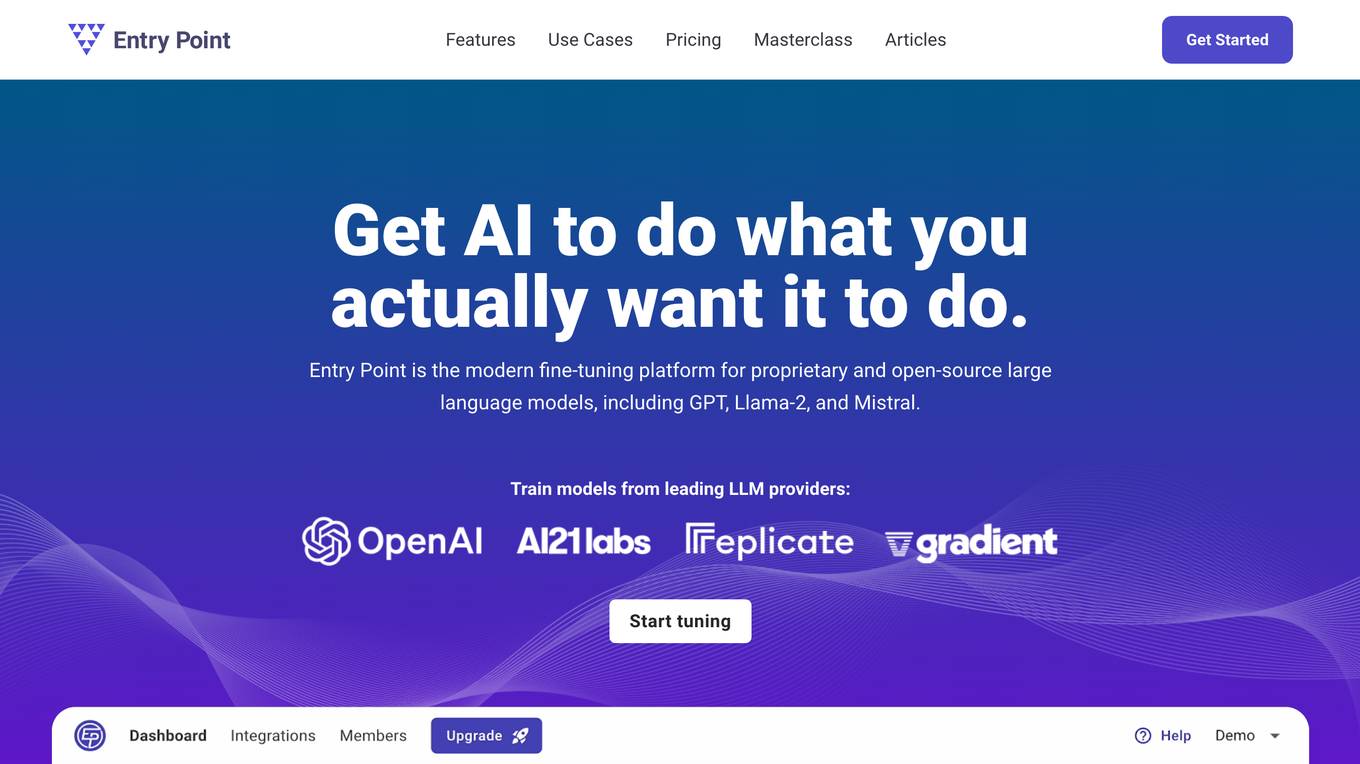
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
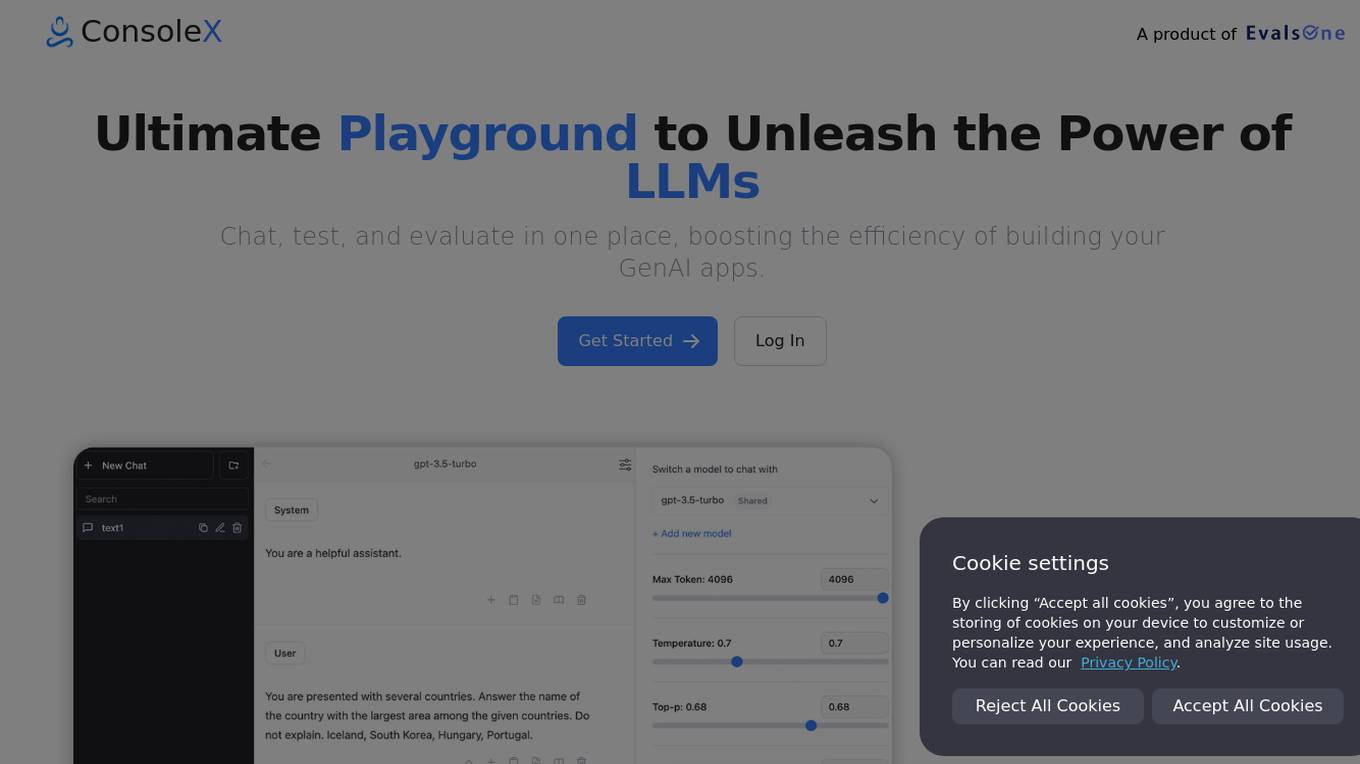
ConsoleX
ConsoleX is an advanced AI tool that offers a wide range of functionalities to unlock infinite possibilities in the field of artificial intelligence. It provides users with a powerful platform to develop, test, and deploy AI models with ease. With cutting-edge features and intuitive interface, ConsoleX is designed to cater to the needs of both beginners and experts in the AI domain. Whether you are a data scientist, researcher, or developer, ConsoleX empowers you to explore the full potential of AI technology and drive innovation in your projects.
Thirdai
Thirdai.com is an AI-powered platform that offers a range of tools and applications to enhance productivity and decision-making. The platform leverages advanced algorithms and machine learning to provide insights and solutions across various domains such as finance, marketing, and healthcare. Users can access a suite of AI tools to analyze data, automate tasks, and optimize processes. With a user-friendly interface and robust features, Thirdai.com is a valuable resource for individuals and businesses seeking to leverage AI technology for improved outcomes.
AiFA Labs
AiFA Labs is an AI platform that offers a comprehensive suite of generative AI products and services for enterprises. The platform enables businesses to create, manage, and deploy generative AI applications responsibly and at scale. With a focus on governance, compliance, and security, AiFA Labs provides a range of AI tools to streamline business operations, enhance productivity, and drive innovation. From AI code assistance to chat interfaces and data synthesis, AiFA Labs empowers organizations to leverage the power of AI for various use cases across different industries.
Upstage
Upstage is an Artificial General Intelligence (AGI) application designed to enhance work productivity by automating simple tasks and providing decision support through generative Business Intelligence (BI) knowledge and numerical understanding. The application offers various features such as Document AI, Solar LLM, and Developers Demo Playground, enabling users to automate tasks, extract key information from documents, and create conversational agents. Upstage aims to streamline workflow automation and improve efficiency in various domains such as healthcare, finance, and law.
Thales Labs AI
Thales Labs is a premier AI research lab and incubator empowering entrepreneurs and domain experts to revolutionize industries with large language models and web3. They focus on fostering innovation in sectors like Insurance, Finance, Healthcare, Pharma, Law, and Journalism. The user-friendly app allows experts to build AI applications using their natural language skills, with support from skilled engineers for complex challenges. Join Thales Labs to transform industries, unlock new opportunities, and create value with AI-driven innovation.
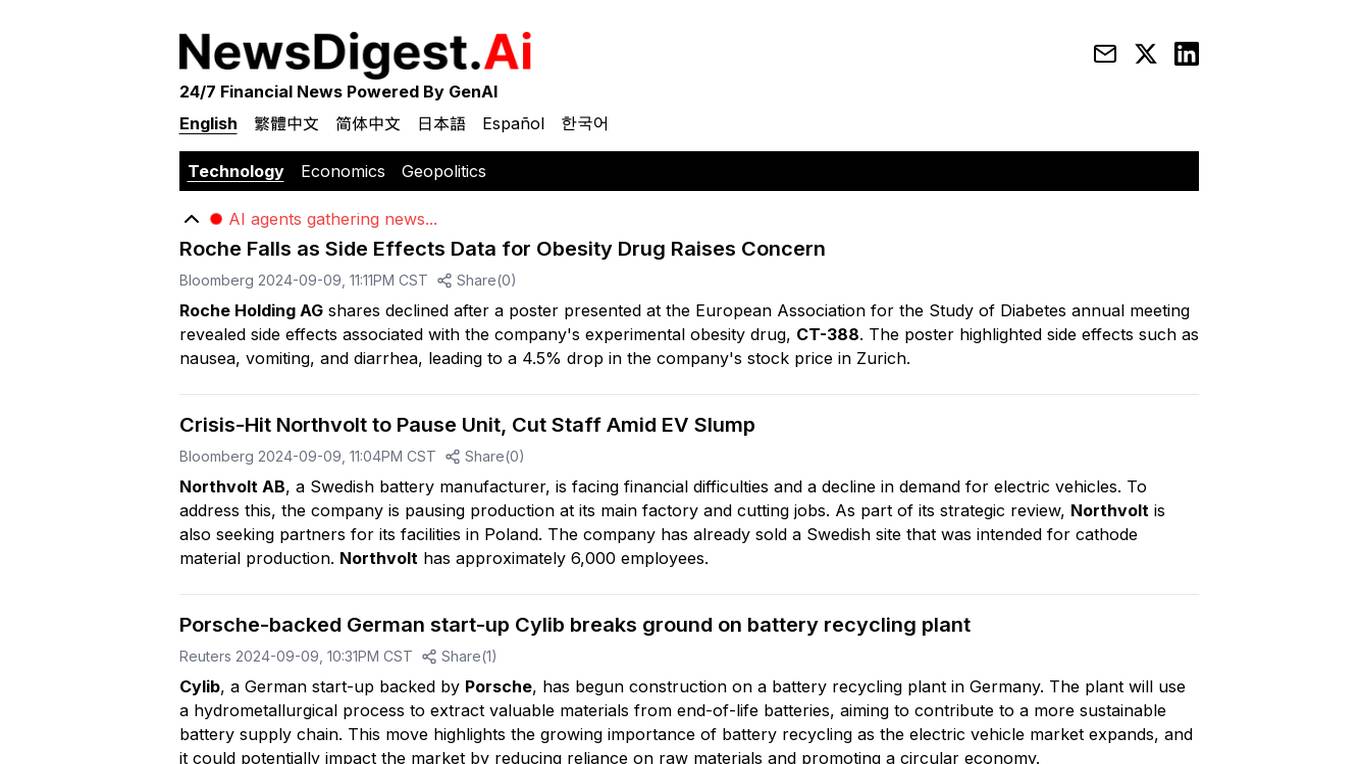
NewsDigest.Ai
NewsDigest.Ai is an AI-powered platform that provides 24/7 financial news updates. It utilizes advanced AI agents to gather news related to technology, economics, and geopolitics in multiple languages. Users can access real-time news content and stay informed about the latest developments in the financial world.
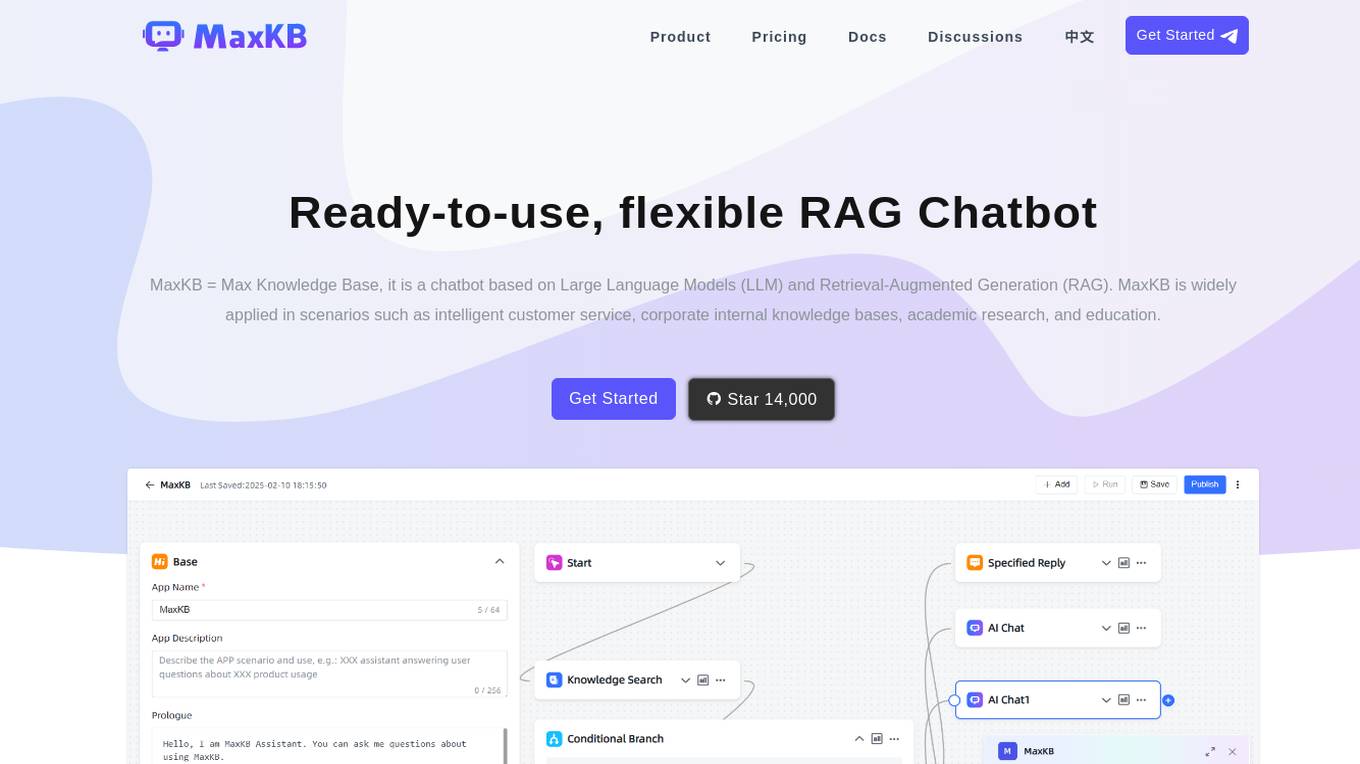
MaxKB
MaxKB is a ready-to-use, flexible RAG Chatbot that is based on Large Language Models (LLM) and Retrieval-Augmented Generation (RAG). It is widely applied in scenarios such as intelligent customer service, corporate internal knowledge bases, academic research, and education. MaxKB supports direct uploading of documents, automatic crawling of online documents, automatic text splitting, vectorization, and RAG for smart Q&A interactions. It also offers flexible orchestration, seamless integration into third-party systems, and supports various large models for enhanced user satisfaction.
LFG GPT
Talk to Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning (LFG)


HaGiPT
Regele GPT ce încearcă să 'paseze' răspunsuri precise și să 'marcheze' puncte cu inteligența sa artificială.





NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence
Large-Language-Models
Large Language Models (LLM) are used to browse the Wolfram directory and associated URLs to create the category structure and good word embeddings. The goal is to generate enriched prompts for GPT, Wikipedia, Arxiv, Google Scholar, Stack Exchange, or Google search. The focus is on one subdirectory: Probability & Statistics. Documentation is in the project textbook `Projects4.pdf`, which is available in the folder. It is recommended to download the document and browse your local copy with Chrome, Edge, or other viewers. Unlike on GitHub, you will be able to click on all the links and follow the internal navigation features. Look for projects related to NLP and LLM / xLLM. The best starting point is project 7.2.2, which is the core project on this topic, with references to all satellite projects. The project textbook (with solutions to all projects) is the core document needed to participate in the free course (deep tech dive) called **GenAI Fellowship**. For details about the fellowship, follow the link provided. An uncompressed version of `crawl_final_stats.txt.gz` is available on Google drive, which contains all the crawled data needed as input to the Python scripts in the XLLM5 and XLLM6 folders.

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.
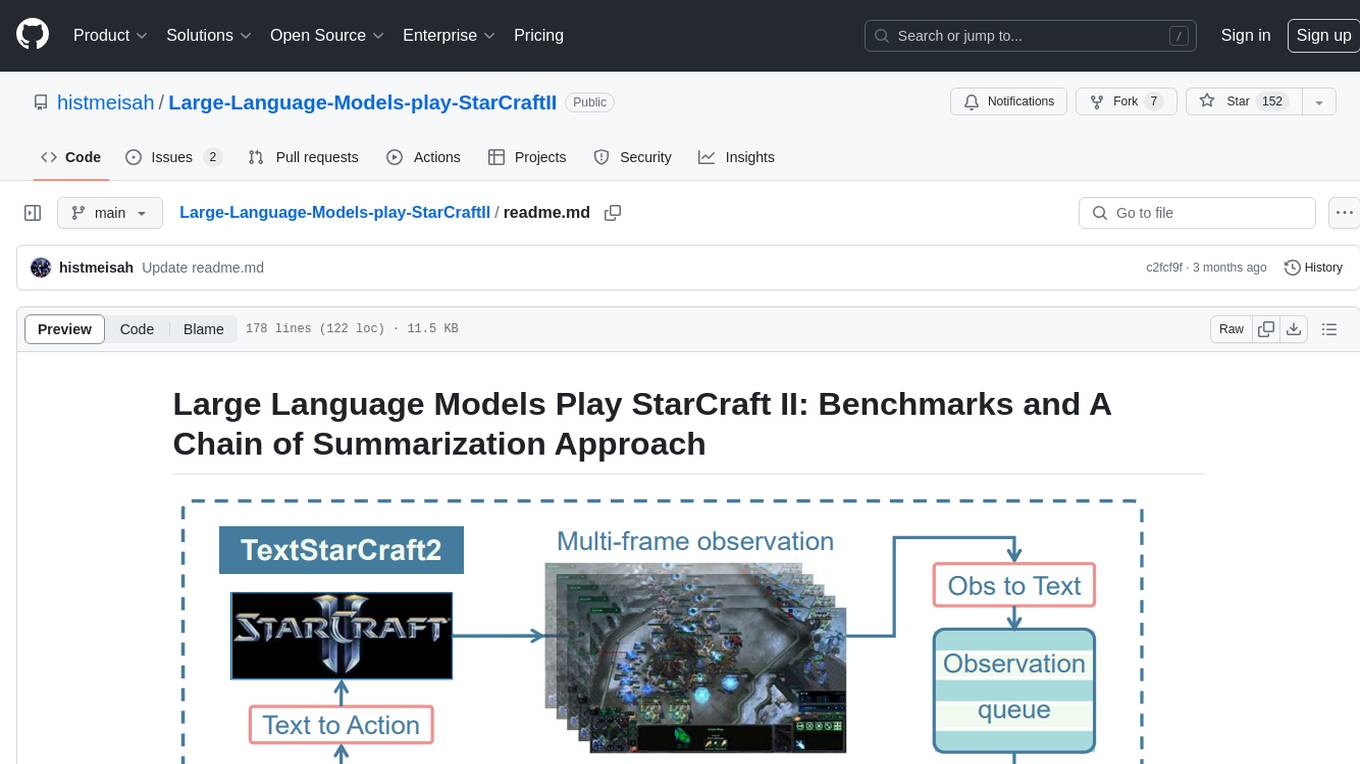
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
modelscope-agent
ModelScope-Agent is a customizable and scalable Agent framework. A single agent has abilities such as role-playing, LLM calling, tool usage, planning, and memory. It mainly has the following characteristics: - **Simple Agent Implementation Process**: Simply specify the role instruction, LLM name, and tool name list to implement an Agent application. The framework automatically arranges workflows for tool usage, planning, and memory. - **Rich models and tools**: The framework is equipped with rich LLM interfaces, such as Dashscope and Modelscope model interfaces, OpenAI model interfaces, etc. Built in rich tools, such as **code interpreter**, **weather query**, **text to image**, **web browsing**, etc., make it easy to customize exclusive agents. - **Unified interface and high scalability**: The framework has clear tools and LLM registration mechanism, making it convenient for users to expand more diverse Agent applications. - **Low coupling**: Developers can easily use built-in tools, LLM, memory, and other components without the need to bind higher-level agents.
evalscope
Eval-Scope is a framework designed to support the evaluation of large language models (LLMs) by providing pre-configured benchmark datasets, common evaluation metrics, model integration, automatic evaluation for objective questions, complex task evaluation using expert models, reports generation, visualization tools, and model inference performance evaluation. It is lightweight, easy to customize, supports new dataset integration, model hosting on ModelScope, deployment of locally hosted models, and rich evaluation metrics. Eval-Scope also supports various evaluation modes like single mode, pairwise-baseline mode, and pairwise (all) mode, making it suitable for assessing and improving LLMs.
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
Awesome-World-Models
This repository is a curated list of papers related to World Models for General Video Generation, Embodied AI, and Autonomous Driving. It includes foundation papers, blog posts, technical reports, surveys, benchmarks, and specific world models for different applications. The repository serves as a valuable resource for researchers and practitioners interested in world models and their applications in robotics and AI.